
下面是机器分布情况:
| 用途 | IP:PORT | 角色 | 主机名 | MongoDB版本 |
| 生产主库 | 172.18.3.167:27101 | Primary | db-test02 | 社区版6.0.4 |
| 生产备库 | 172.18.3.168:27101 | Secondary | db-test03 | 社区版6.0.4 |
| 恢复机器 | 172.18.3.166:27101 | 无 | db-test01 | 社区版6.0.4 |
mongodump版本:100.7.0
mongodump version: 100.7.0
git version: 17946f45f5fabfcdd99f8960b9109f976d370631
Go version: go1.19.6
os: linux
arch: amd64
compiler: gc大致步骤
- 导出
oplog,可以在主库或者备库导; - 寻找oplog中误操作发生的时间戳;
- 全备+增备重放到误操作的前一刻;
- 将恢复的数据dump/restore到生产库;
模拟步骤
1. 首先我们往生产集群一个集合t1里插入部分测试数据。
ycf [direct: primary] mydb> for (var i=0; i < 1000; i++) { db.t1.insert({"a":i}) }
{
acknowledged: true,
insertedIds: { '0': ObjectId("65239d51fa195c51fa67afde") }
}
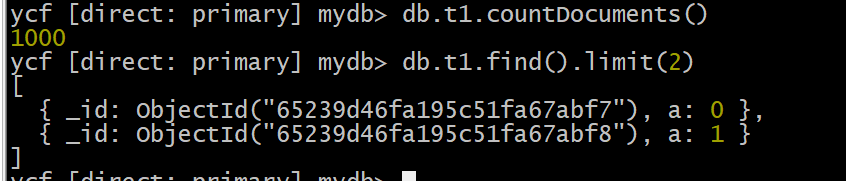
2. 检查下collection t1中的数据
总共1000条
3. 开始备份
直接采用物理备份,在备节点锁定之后直接拷贝物理文件
db.fsyncLock()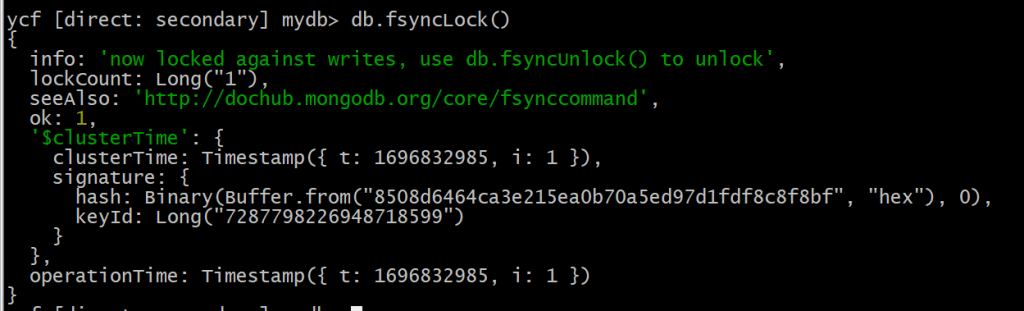
在备节点 172.18.3.168上直接将所有数据文件拷贝到恢复机器172.18.3.166上
scp -r /usr/local/data/mongodb/data/* 172.18.3.166:/usr/local/data/mongodb/data/备份完成,解锁
db.fsyncUnlock()
4. 恢复机器172.18.3.166上启动实例
正常启动之后,此时相当于全备已经恢复完成了。
/usr/local/data/mongodb/bin/mongod -f /usr/local/data/mongodb/param/mongodb.conf
5. 继续往生产集群中插入一条记录,然后等待几秒后再不带条件的remove(remove({}))
db.t1.insert({"a":20000})
db.t1.countDocuments()
db.t1.remove({})
t1这张表全部没有了,我们假设最后remove({})是误操作,现在需求是要求数据恢复到误操作之前,总数据量是1001条数据
6. 先备份一次oplog(在主库和备库都可以)
mongodump mongodb://admin:admin_pwd@127.0.0.1:27101 --authenticationDatabase admin -d local -c oplog.rs -o /tmp/oplog/
#并且复制oplog文件到恢复机器上
scp -r /tmp/oplog 172.18.3.166:/tmp/ 
7. 找到误操作时间戳,并导出上一次备份到误操作前的oplog
db.oplog.rs.find({"op" : "d", "ns" : "mydb.t1"}).sort({ts:1}).limit(3)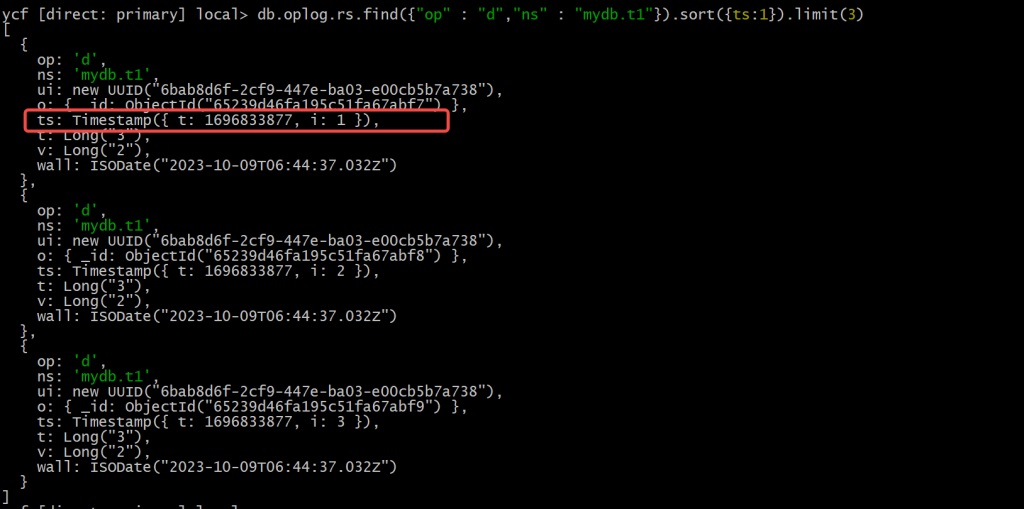
可以发现误操作的时间点是在(1696833877,1)。
8. 在恢复机器上开始恢复
因为该机器上刚才恢复的全备数据库已经有集群信息了,所以要做下特殊处理,修改一下副本集集群信息。如果重新初始化会看到如下信息:

conf = rs.conf()
delete conf.members[1] #删除多余的member
conf.members[0].host = "172.18.3.166:27101"
rs.reconfig(conf, {force:1}) #强制重新配置副本集开始应用oplog,做定点恢复,此时不能指定库名和集合名,会报错。
mongorestore mongodb://admin:admin_pwd@127.0.0.1:27101 --authenticationDatabase admin \
--oplogReplay \
--oplogFile /tmp/oplog/local/oplog.rs.bson \
--oplogLimit 1696833877:1
# --oplogReplay replay oplog for point-in-time restore
# --oplogLimit=<seconds>[:ordinal] only include oplog entries before the provided Timestamp
# --oplogFile=<filename> oplog file to use for replay of oplog恢复成功,因为有些表记录已经存在了,所以恢复时会直接报记录重复错误,并且提示会有部分文档恢复失败,忽略即可
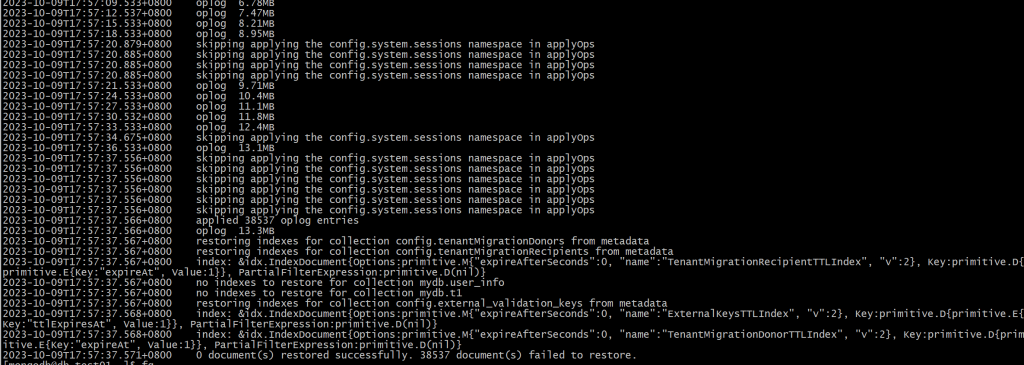
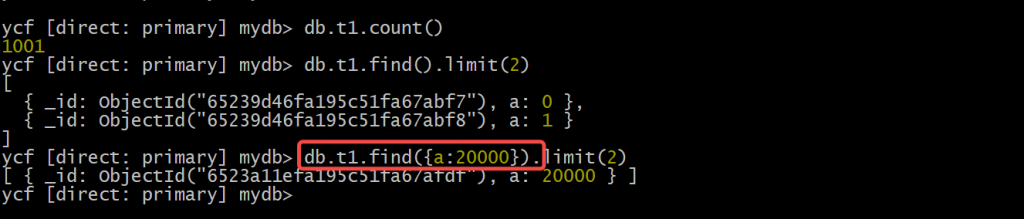
9. 查看恢复之后的数据
最后插入的{a: 20000}这条数据也存在了,t1集合总数据量1001,符合恢复预期
10. 将恢复之后的数据重新dump/restore到生产数据库
省略,自行操作。
可以优化的步骤
因为丢失的只有一个表,我们却恢复了整个数据库,消耗了不必要的时间, 因为我们导出oplog时候没有添加过滤条件
因此我们可以设置以下几个过滤条件:
- 设置起止时间:开始时间在全备之前({“wall” : ISODate(‘2023-10-08T16:00:00.000Z’)}),结束时间截止为误操作时间({“ts”: Timestamp({t: 1696833877, i: 1 })})。
- 只导出mydb.t1这个表的oplog({“ns”: “mydb.t1”})。
mongodump mongodb://admin:admin_pwd@127.0.0.1:27101 --authenticationDatabase admin \
-d local \
-c oplog.rs \
-q '{"$and": [{"ns": "mydb.t1"}, {"wall":{"$gte": { "$date": "2023-10-08T16:00:00.000Z"}}}, {"ts":{"$lt": {"$timestamp": {"t": 1696833877, "i": 1}}}} ]}' \
-o oplog/这样过滤之后oplog里面的内容将会少很多,能节省大量的恢复时间。
上面的命令有一个bug,那就是有可能存在事务的情况,事务会将所有的操作都放在一个条oplog里面,但是在oplog中ns字段却不是mydb.t1。
列如事务如下:
var mongo = db.getMongo();
var session = mongo.startSession();
session.startTransaction();
var coll = session.getDatabase("mydb").getCollection("t1");
coll.insertOne({a: 50000});
coll.insertOne({a: 50001});
coll.insertOne({a: 50000});
session.commitTransaction();产生的oplog如下:
{
lsid: {
id: new UUID("926b0659-2dbf-4b7e-8384-d66956def791"),
uid: Binary(Buffer.from("3b408cb48548b5037822c10eb0976b3cbf2cee3bf9c708796bf03941fbecd80f", "hex"), 0)
},
txnNumber: Long("1"),
op: 'c',
ns: 'admin.$cmd',
o: {
applyOps: [
{
op: 'i',
ns: 'mydb.t1',
ui: new UUID("6bab8d6f-2cf9-447e-ba03-e00cb5b7a738"),
o: { _id: ObjectId("6524cc22436cd6fa89f1a824"), a: 50000 },
o2: { _id: ObjectId("6524cc22436cd6fa89f1a824") }
},
{
op: 'i',
ns: 'mydb.t1',
ui: new UUID("6bab8d6f-2cf9-447e-ba03-e00cb5b7a738"),
o: { _id: ObjectId("6524cc22436cd6fa89f1a825"), a: 50001 },
o2: { _id: ObjectId("6524cc22436cd6fa89f1a825") }
},
{
op: 'i',
ns: 'mydb.t1',
ui: new UUID("6bab8d6f-2cf9-447e-ba03-e00cb5b7a738"),
o: { _id: ObjectId("6524cc22436cd6fa89f1a826"), a: 50000 },
o2: { _id: ObjectId("6524cc22436cd6fa89f1a826") }
}
]
},
ts: Timestamp({ t: 1696910371, i: 1 }),
t: Long("3"),
v: Long("2"),
wall: ISODate("2023-10-10T03:59:31.458Z"),
prevOpTime: { ts: Timestamp({ t: 0, i: 0 }), t: Long("-1") }
}所以还要加一个事务的过滤条件,最终命令如下:
mongodump mongodb://admin:admin_pwd@127.0.0.1:27101 --authenticationDatabase admin \
-d local \
-c oplog.rs \
-q '{"$and": [ {"$or":[{"o.applyOps.ns": "mydb.t1"},{"ns": "mydb.t1"}]}, {"wall":{"$gte": { "$date": "2023-10-08T16:00:00.000Z"}}}, {"ts":{"$lt": {"$timestamp": {"t": 1696833877, "i": 1}}}} ]}' \
-o oplog/恢复过程可能遇到的问题
1. mongodump导出oplog时常规写法使用wall或者ts字段无法过滤,ns字段能正常过滤。
mongodump mongodb://admin:admin_pwd@127.0.0.1:27101 --authenticationDatabase admin \
-d local \
-c oplog.rs \
-q '{"$and": [{"ns": "mydb.t1"}, {"wall":{"$gte": "ISODate('2023-10-08T16:00:00.000Z')"}}, {"ts":{"$lt": "Timestamp({'t': 1696833877, 'i': 1 })"}} ] }' \
-o oplog/ 
这里明明oplog有数据,但是却导出0 documents,这是因为写法不对,要做下相应的转换,使用$timestamp和$data操作符
{"wall":{"$gte": "ISODate('2023-10-08T16:00:00.000Z')"}} 换成 {"wall":{"$gte": { "$date": "2023-10-08T16:00:00.000Z"}}}
{"ts":{"$lt": "Timestamp({'t': 1696833877, 'i': 1 })"}} 换成 {"ts":{"$lt": {"$timestamp": {"t": 1696833877, "i": 1}}}}最终的导出命令命令如下(注意区别):
mongodump mongodb://admin:admin_pwd@127.0.0.1:27101 --authenticationDatabase admin \
-d local \
-c oplog.rs \
-q '{"$and": [ {"$or":[{"o.applyOps.ns": "mydb.t1"},{"ns": "mydb.t1"}]}, {"wall":{"$gte": { "$date": "2023-10-08T16:00:00.000Z"}}}, {"ts":{"$lt": {"$timestamp": {"t": 1696833877, "i": 1}}}} ]}' \
-o oplog/