
背景
我们生产上有一套MongoDB,架构为分片架构,版本4.4,后端为三分片节点,2个Mongos,从最近的监控中经常能发现类似如下监控数据,各个几点直接TPS严重不均衡,如下只是一个性能倾斜示例图,并不是该集群实际的监控图。
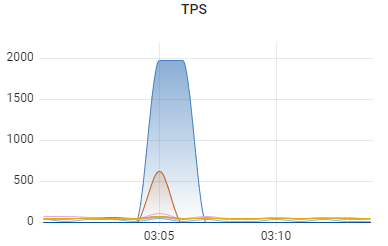
经过排查发现是数据在写入的时候就已经不均衡了,最终定位到是分片集合的分片方式不合理,排查思路是关闭均衡器(rebalancer),通过分析后端各个分片节点的oplog来分析问题发生时实际的数据分布。
在我们的业务场景中, 存在如下两个特点:
- 所有的业务查询修改删除都会走分片键
- 所有的业务查询修改删除均为点查,一次性只操作一条记录,不存在范围查询。
基于上面两个特点,集合的分片方式设定为hash模式是最佳的。
sh.enableSharding('appdb')
sh.shardCollection("appdb.user_role_info", {user_id: 'hashed'} ); 但是这些集合刚好没有才用hash分片模式,而才用的range分片模式。
sh.enableSharding('appdb')
sh.shardCollection("appdb.user_role_info", {user_id: 1} ); 这样一来,该分片模式下后续就会有很大的性能瓶颈,最典型的是无法有效扩展DML的能力,应用负载会偏向部分节点,解决办法当然是协商找停机维护时间,调整分片模式,MongoDB目前还没法直接在线修改分片模式。
MongoDB提供两种分片模式,一个范围(ranged)分片,另一个哈希(hash)分片。
Ranged分片
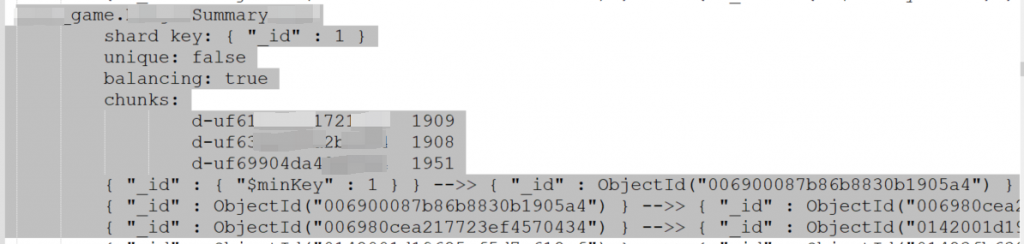
范围分片是MongoDB默认的分片模式,原理图如下,很容易想到如果分片键是一段连续的值大概率这部分内容都会落在同一个chunk, 从而造成分片节点之间性能倾斜。

使用如下命令可以详细列出每一个chunk的数据分布
sh.status({verbose:1})如下是一个Range分片的实际的例子:
哈希分片
哈希分片其实将分片键的值在Mongos组件处主动使用hash函数计算了一遍,将计算之后的值再然按范围分片来做拆分,由于经过了一次hash,所以使得分片键的值更为随机,也更能覆盖到各个shard节点,性能更容易打散,不容易产生倾斜,但hash分片典型的弊端是范围查询比较低效,因为所有的范围查询都要下发到所有的后端节点

如下是一个Hashed分片的实际的例子:

最后
选择哪一种的分片方式需要结合实际的业务来看,力求完美避开两种模式的弊端,扬长避短,DBA千万不能只站在数据库层面来看待问题,要学会结合实际业务来思考最佳的数据模型,要做一个既懂业务又懂数据库的DBA。